Domain Adaptation Without Source Data

Deep Domain Adaptation In Computer Vision By Branislav Hollander Towards Data Science
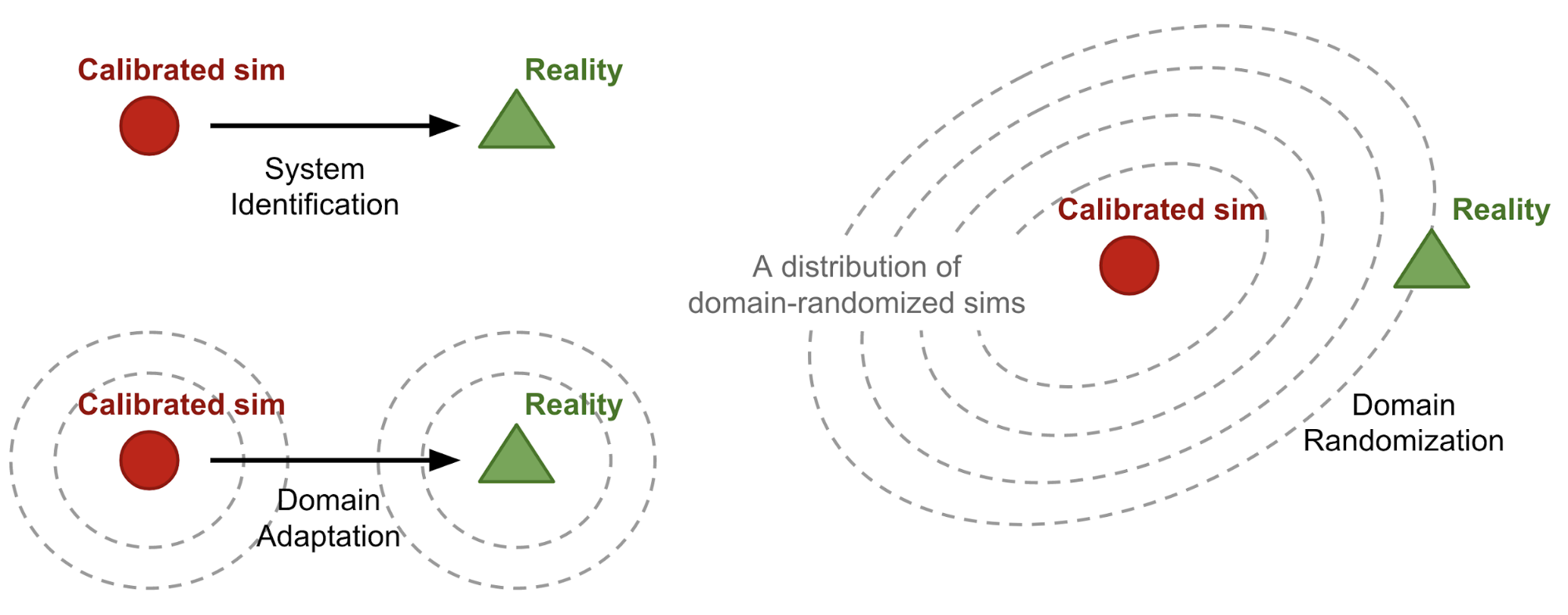
Domain Randomization For Sim2real Transfer

Domain Adaptation Papers With Code

A Comprehensive Hands On Guide To Transfer Learning With Real World Applications In Deep Learning Deep Learning Learning Strategies Learning
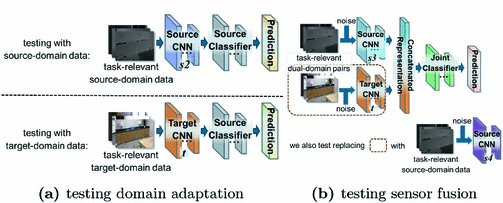
Zero Shot Deep Domain Adaptation Springerlink

Oracle Blogs Oracle For Startups In 2020 Oracle Certification Customer Success Stories Job Satisfaction
Configure virtual anaconda environment.
Domain adaptation without source data. 0 share. Rules trained on source data and made ready for a direct deployment and later reuse. Unsupervised domain adaptation without source data by casting a bait.
These procedures are often presented in the form of classification identification ranking etc. However such an assumption is rarely plausible in real cases and possibly causes data privacy issues especially when the label of the source domain can be a sensitive attribute as an identifier. Prior uda methods typically require to access the source data when learning to adapt the model making them risky and inefficient for decentralized private data.
This work tackles a practical setting where only a trained source model is. 10 23 2020 by shiqi yang et al. Existing uda methods require access to the data from the source domain during adaptation to the target domain which may not be feasible in some real world situations.
Unsupervised domain adaptation without source data rui li1 qianfen jiao1 wenming cao3 hau san wong1 si wu2 1department of computer science city university of hong kong 2school of computer science and engineering south china university of technology 3department of statistics and actuarial science the university of hong kong. Sfda domain adaptation without source data sfda train py jump to code definitions seed everything function source fixednet class init function target trainablenet class init function. Domain adaptation assumes that samples from source and target domains are freely accessible during a training phase.
Unsupervised domain adaptation without source data abstract. Python 3 6 pytorch 1 5 recent version is recommended nvidia gpu 12gb cuda 10 0 optional cudnn 7 5 optional getting started installation. Unsupervised domain adaptation uda aims to transfer the knowledge learned from labeled source domain to unlabeled target domain.
To avoid accessing source data which may contain sensitive information we. However such an assumption is rarely plausible in real cases and possibly causes data privacy issues especially when the label of the source domain can be a sensitive attribute as an identifier. When source domain data can not be accessed decision making procedures are often available for adaptation nevertheless.
Https Arxiv Org Pdf 1904 02817
Https Openaccess Thecvf Com Content Cvpr 2018 Papers Volpi Adversarial Feature Augmentation Cvpr 2018 Paper Pdf

Deep Visual Domain Adaptation A Survey Sciencedirect

Active Multi Kernel Domain Adaptation For Hyperspectral Image Classification Sciencedirect
Https Arxiv Org Pdf 1907 10915
Https Arxiv Org Pdf 1702 08811
Https Arxiv Org Pdf 1705 10667
Https Openaccess Thecvf Com Content Cvpr 2018 Papers Hu Duplex Generative Adversarial Cvpr 2018 Paper Pdf

Open Source Challenges As Advanced Analytics Solutions Predictive Analytics Data Science Analytics

The Reality Of Ar Vr Business Models Digital Transformation Reality Mobile Data

The 7 Habits Of Highly Effective Ar Vr Startups Augmented Reality Start Up Reality
Https Openaccess Thecvf Com Content Cvpr 2019 Papers Vu Advent Adversarial Entropy Minimization For Domain Adaptation In Semantic Segmentation Cvpr 2019 Paper Pdf
